
This post was updated 1344 days ago and some of the ideas may be out of date.
分表的时候,一般都是用主键进行hash取模计算出落库表名,或者直接生成分布式全局唯一id,然后按2^n 取模,把一张表,分成多张表。那么这样分表有什么缺陷呢?
例如用户表,通过用户ID取模,把数据分布到不同的表,这样每次通过用户ID取模就能计算出落库的表名。万一要使用username、phone、email、.... ,就没办法直接计算出落地表名。
一般方案:
通过中间表映射
用户表(user1)
| id | username |
| 10000 | test |
中间表(username_find_user)
| username | table | id |
| test | user1 | 10000 |
先使用用户名通过username_find_user表查询出用户id,再通过用户id取模查询用户信息,这种方案太消耗资源,而且效率低。
基因算法方案:
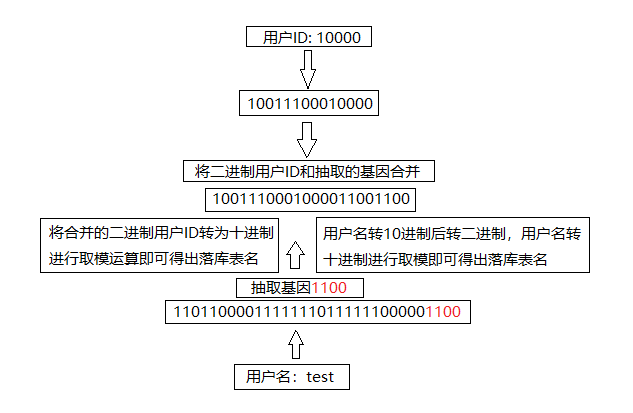
分表数量8张,用户ID为10000,用户名为test
用户名转十进制整数:3632233996
取出用户名基因:用户名的二进制是11011000011111110111111000001100取出后4位(因为LOG(8,2)=4)就是1100
用户ID转为二进制:10011100010000
生成新的二进制用户ID: 100111000100001100 加上4位取出的用户ID基因
新的用户ID:160012,由二进制转为十进制所得
新的用户ID落库表名为4,计算方法 用户ID和分表数量进行取模运算即:160012 % 8 = 4
用户名转整数后计算出的落库表名:4,计算方法:3632233996 % 8 = 4
PHP示例代码:
<?php
/**
* Created by PhpStorm.
* User: LinFei
* Created time 2022/10/14 14:51:52
* E-mail: fly@eyabc.cn
*/
declare (strict_types=1);
// 分库分表使用 用户名 和 用户ID都能查询出落库的表名
// 分表数量 只能是1、2、4、8、16、32、64、128、256、512、1024、2048、4096、..., 否则会出现匹配错误的情况
$tableNumber = 4096;
// 随机生成的用户名
$username = date('YmdHisU');
// 随机生成的用户ID
$userId = (int)(time() . mt_rand(100, 10000));
// 用户名转二进制
$userNameBin = decbin((int)sprintf("%u", crc32($username)));
// 用户ID转二进制
$userIdBin = decbin($userId);
// 新的用户ID
$userId = bindec($userIdBin . substr($userNameBin, -(int)log($tableNumber, 2)));
// 用户ID落库表名
$userIdTable = $userId % $tableNumber;
// 用户名落库表名
$userNameTable = bindec($userNameBin) % $tableNumber;
var_dump([
'userId' => $userId,
'userName' => $username,
'userIdTable' => $userIdTable,
'userNameTable' => $userNameTable,
]);
// 用户ID落库表名
var_dump($userId % $tableNumber);
// 用户名落库表名
var_dump((int)sprintf("%u", crc32($username)) % $tableNumber);

参与讨论